
JBoss Tools 4.5.0.AM1 for Eclipse Oxygen.0
Happy to announce 4.5.0.AM1 (Developer Milestone 1) build for Eclipse Oxygen.0.
Downloads available at JBoss Tools 4.5.0 AM1.
What is New?
Full info is at this page. Some highlights are below.
Server Tools
EAP 7.1 Server Adapter
A server adapter has been added to work with EAP 7.1. It’s currently released in Tech-Preview mode only, since the underlying WildFly 11 continues to be under active development with substantial opportunity for breaking changes. This new server adapter includes support for incremental management deployment like it’s upstream WildFly 11 counterpart.
Hibernate Tools
Hibernate Search Support
We are glad to announce the support of the Hibernate Search. The project was started by Dmitrii Bocharov in the Google Summer Code program and has been successfully transferred in the current release of the JBoss Tools from Dmitrii’s repository into the jbosstools-hibernate repository and has become a part of the JBoss family of tools.
Functionality
The plugin was thought to be some kind of a Luke tool inside Eclipse. It was thought to be more convenient than launching a separate application, and picks up the configuration directly from your Hibernate configuration.
Two options were added to the console configurations submenu: Index Rebuild and Index Toolkit. They become available when you use hibernate search libraries (they exist in the build path of your application, e.g. via maven).
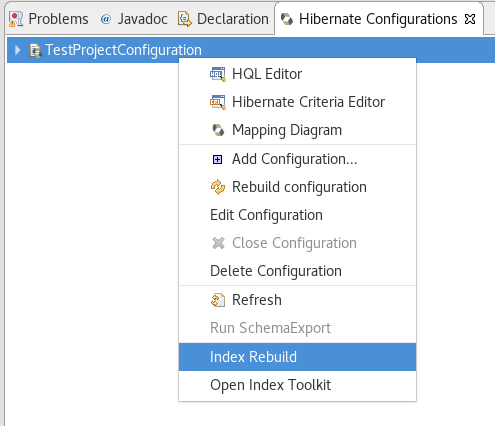
Index Rebuild
When introducing Hibernate Search in an existing application, you have to create an initial Lucene index for the data already present in your database.
The option "Index Rebuild" will do so by re-creating the Lucene index in the directory specified by the hibernate.search.default.indexBase property.
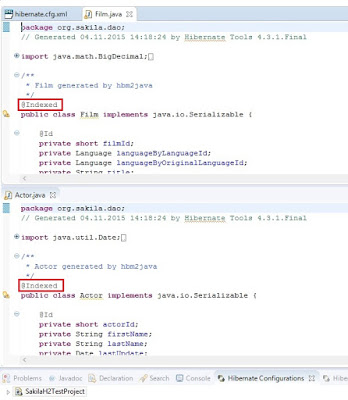
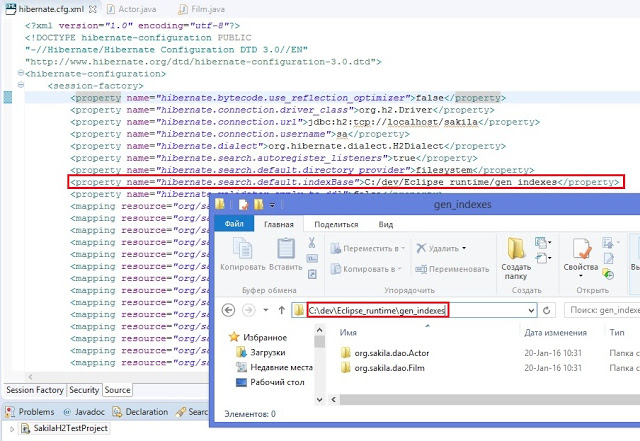
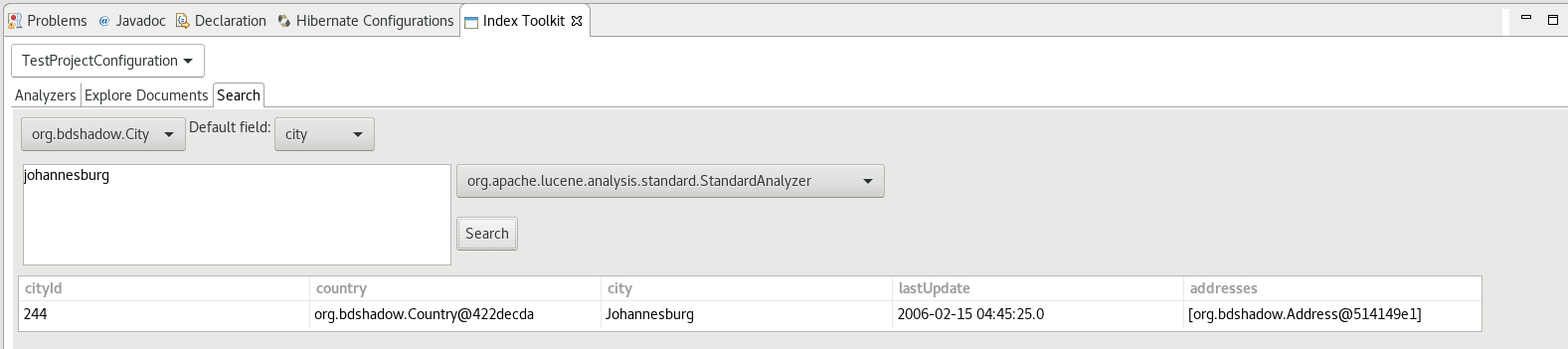
Index Toolkit
"Open Index Toolkit" submenu of the console configuration opens an "Index Toolkit" view, which has three tabs: Analyzers, Explore Documents, Search.
Analyzers
This tab allows you to view the result of work of different Lucene Analyzers. The combo-box contains all classes in the workspace which extend org.apache.lucene.analysis.Analyzer, including custom implementations created by the user. While you type the text you want to analyse, the result immediately appears on the right.

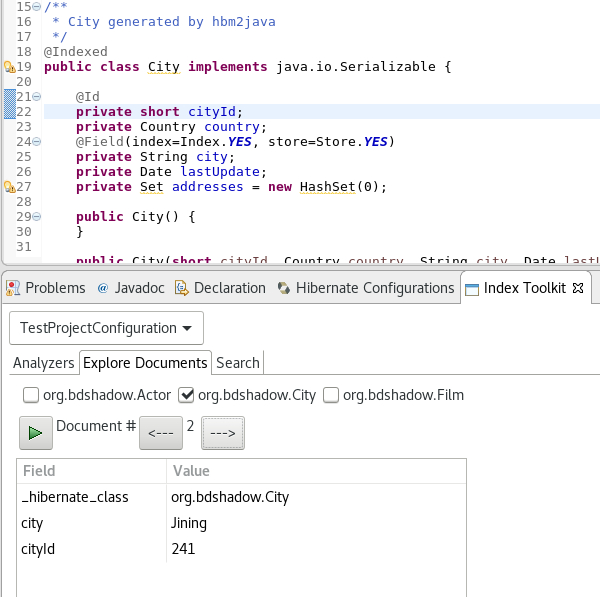
Explore Documents
After creating the initial index you can now inspect the Lucene Documents it contains.
All entities annotated as @Indexed are displayed in the Lucene Documents tab.
Tick the checkboxes as needed and load the documents. Iterate through the documents using arrows.
Searching
The plugin passes the input string from the search text box to the QueryParser which parses it using the specified analyzer and creates a set of search terms, one term per token, over the specified default field. The result of the search pulls back all documents which contain the terms and lists them in a table below.
Forge
Forge Runtime updated to 3.7.1.Final
The included Forge runtime is now 3.7.1.Final. Read the official announcement here.
Enjoy!
Jeff Maury
