What's New in 4.5.0.Final
General
Fuse Tooling integration
Fuse Tooling was previously part of JBoss Tools Integration Stack. It is now part of JBoss Tools itself for easier availability of development of Fuse integration projects. If you don’t know yet about this project, please have a look to this short overview.
Docker Tools
Docker Client Upgrade
The version of docker-client used by the Docker Tooling plug-ins has been upgraded to 6.1.1 for the 3.0.0 release of the Docker Tooling feature.
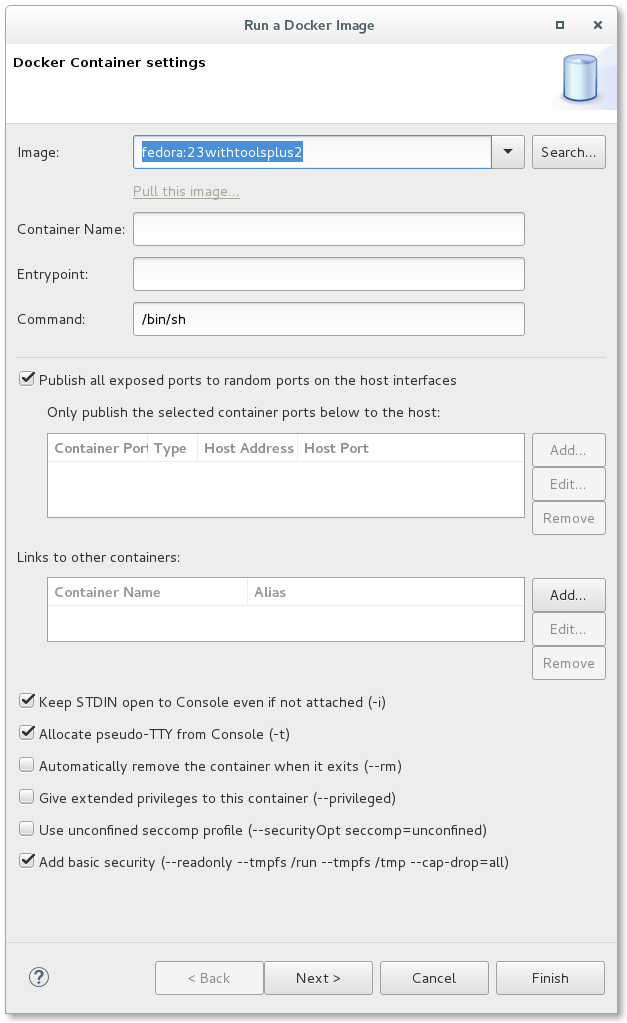
New Basic Security Option
Support has been added to the Run Image Wizard to add a basic security option. When chosen, this option behaves the same as using "docker run --cap-drop=all --readonly --tmpfs /run --tmpfs /tmp". In addition to dropping extraneous capabilities, the basic option makes all non-mounted directories read-only and mounts /run and /tmp into tmpfs which is cleared on each start of the container.
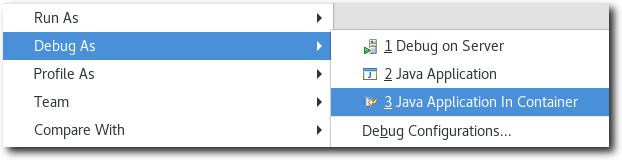
Docker Tooling JDT Integration
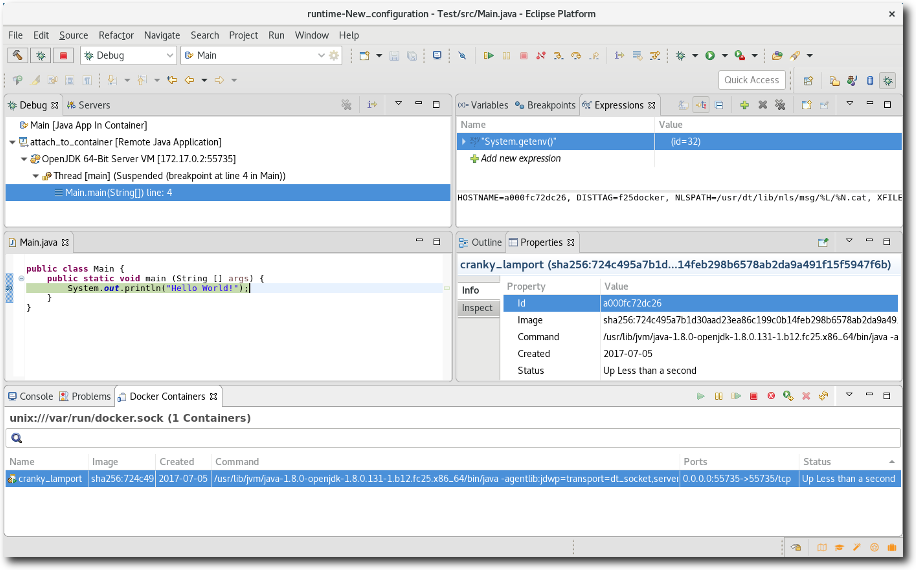
The Eclipse Docker Tooling Feature now contains a plugin that integrates with the Java Development Tools (JDT). This permits the running and debugging of Eclipse Java projects within containers. The functionality is provided through the context menu under the 'Run As' and 'Debug As' options. The daemon connection used, as well as the image chosen are configurable through launch configurations.
This is intended to work in the same way that a regular run/debug session works.
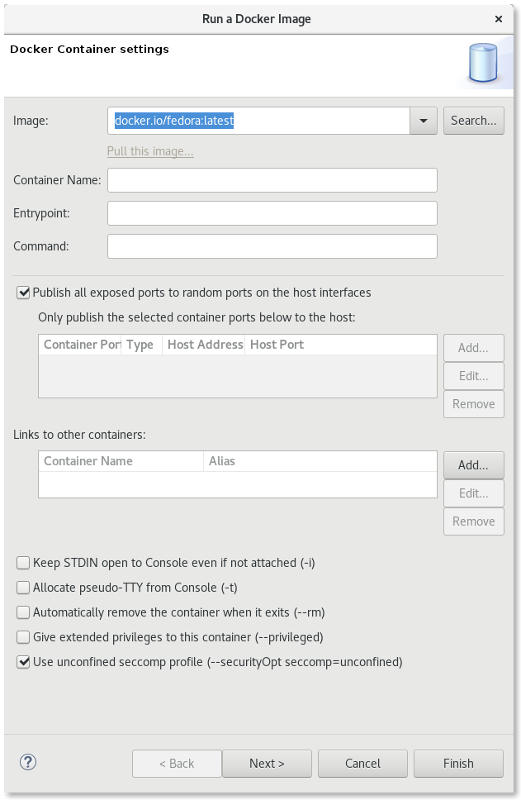
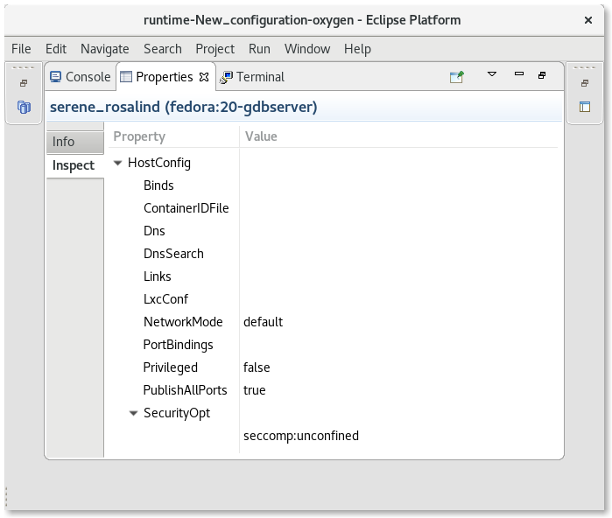
New Security Options
Support has been added when launching commands in a Container to specify a security option profile. This can be done in lieu of specifying privileged mode. For example, to run gdbserver, one can specify "seccomp:unprofiled" to allow ptrace commands to be run by the gdb server.
The Run Image Wizard has been modified to allow specifying an unconfined seccomp profile to replace the default seccomp profile.
Security options are also now shown in the Properties View.
Forge Tools
Forge Runtime updated to 3.7.2.Final
The included Forge runtime is now 3.7.2.Final. Read the official announcement here.
Freemarker
Freemarker component deprecation
The Freemarker component has been marked deprecated as there is no more maintenance on the source code. It is still available in Red Hat Central and may be removed in the future.
Related JIRA: JBIDE-24484
Fuse Tooling
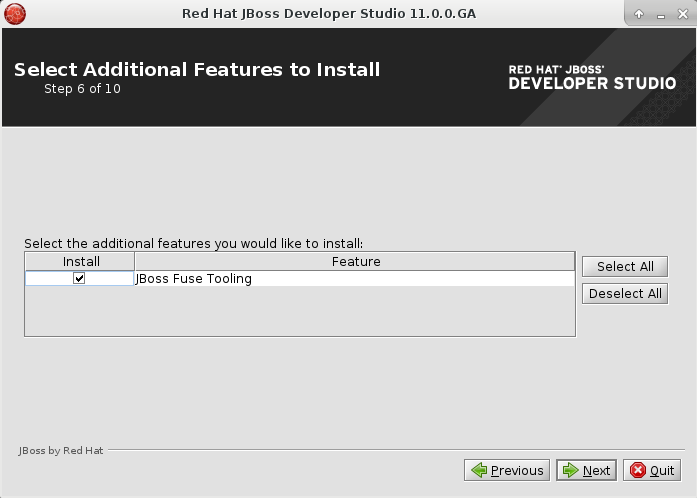
Devstudio installer
Fuse Tooling is now available from within the Red Hat JBoss Developer Studio installer, as an additional feature to install.
Bean Support
We are happy to finally announce support for Beans (Spring / Blueprint).
Using the Route Editor you can now access Spring / Blueprint Beans in your Camel Context through the Configurations tab.
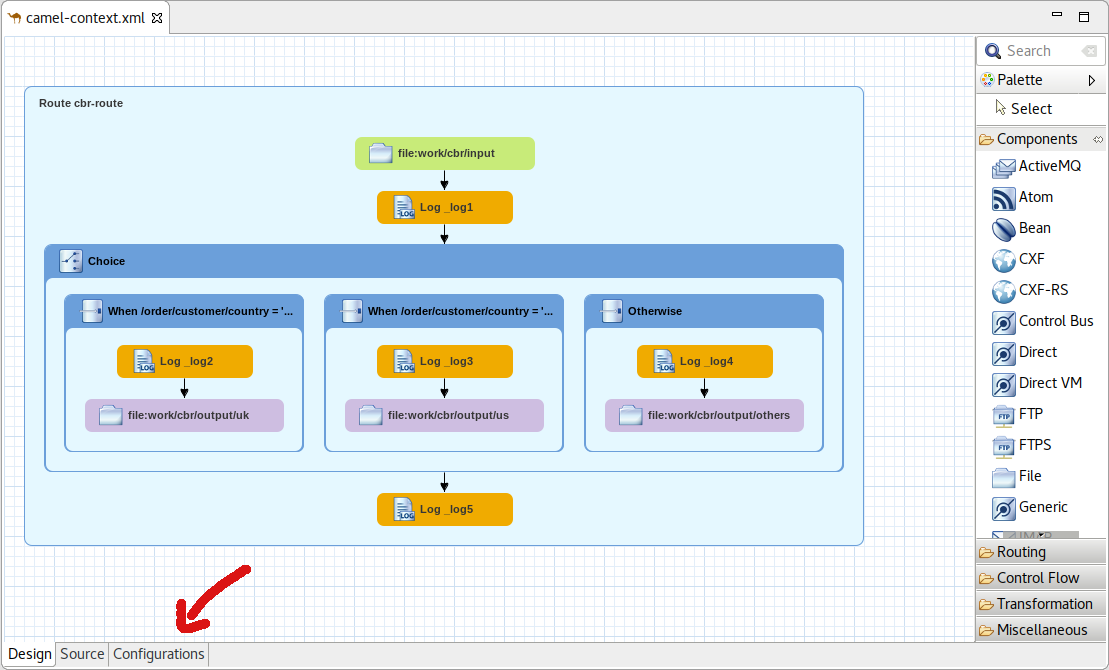
In the Configurations tab you can see all global configuration elements of your Camel Context. You can Add, Edit and Delete elements using the buttons on the right side.

By clicking the Add or Edit button a wizard will be opened to guide you on the creation of the Bean.
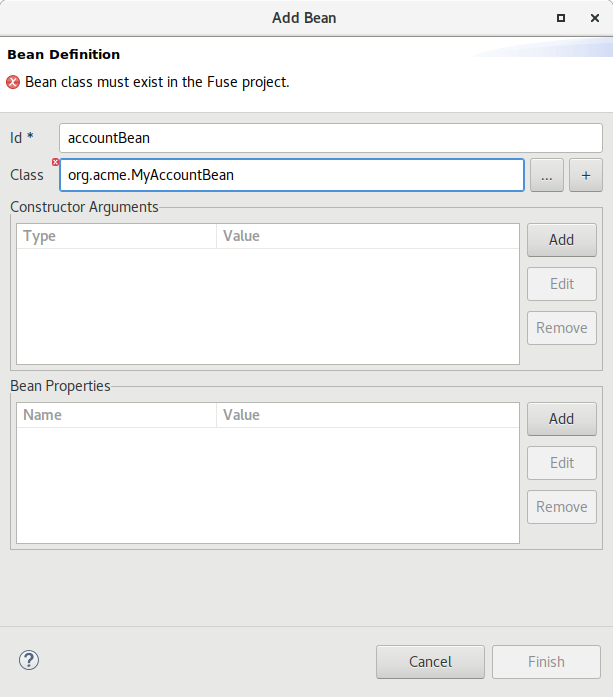
In the wizard you can select an existing bean class from your project or create a new bean class. You can also specify constructor arguments and bean properties.
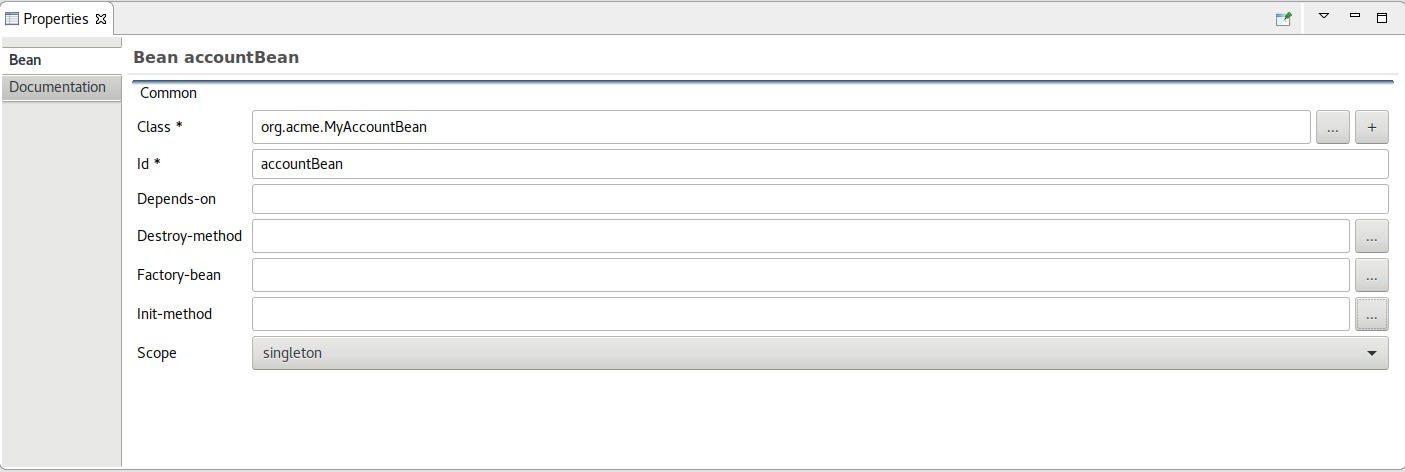
Once created you can then modify the properties of that Bean inside the Properties view.
Hibernate Tools
Hibernate Search Support
We are glad to announce the support of the Hibernate Search. The project was started by Dmitrii Bocharov in the Google Summer Code program and has been successfully transferred in the current release of the JBoss Tools from Dmitrii’s repository into the jbosstools-hibernate repository and has become a part of the JBoss family of tools.
Functionality
The plugin was thought to be some kind of a Luke tool inside Eclipse. It was thought to be more convenient than launching a separate application, and picks up the configuration directly from your Hibernate configuration.
Two options were added to the console configurations submenu: Index Rebuild and Index Toolkit. They become available when you use hibernate search libraries (they exist in the build path of your application, e.g. via maven).
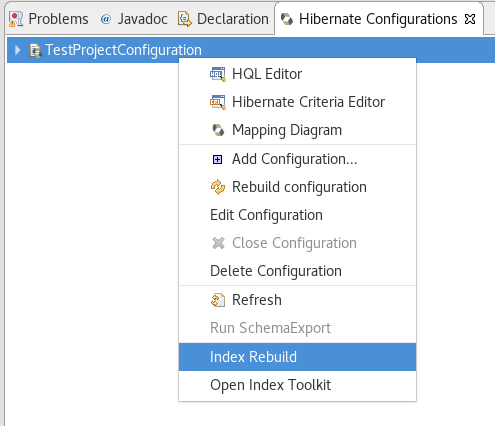
Index Rebuild
When introducing Hibernate Search in an existing application, you have to create an initial Lucene index for the data already present in your database.
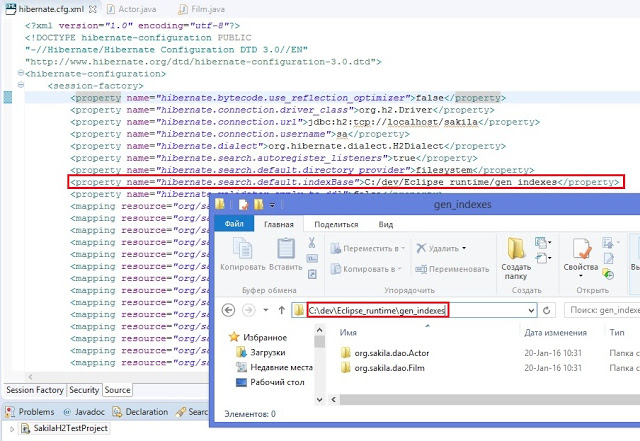
The option "Index Rebuild" will do so by re-creating the Lucene index in the directory specified by the hibernate.search.default.indexBase property.
Index Toolkit
"Open Index Toolkit" submenu of the console configuration opens an "Index Toolkit" view, which has three tabs: Analyzers, Explore Documents, Search.
Analyzers
This tab allows you to view the result of work of different Lucene Analyzers. The combo-box contains all classes in the workspace which extend org.apache.lucene.analysis.Analyzer, including custom implementations created by the user. While you type the text you want to analyse, the result immediately appears on the right.

Explore Documents
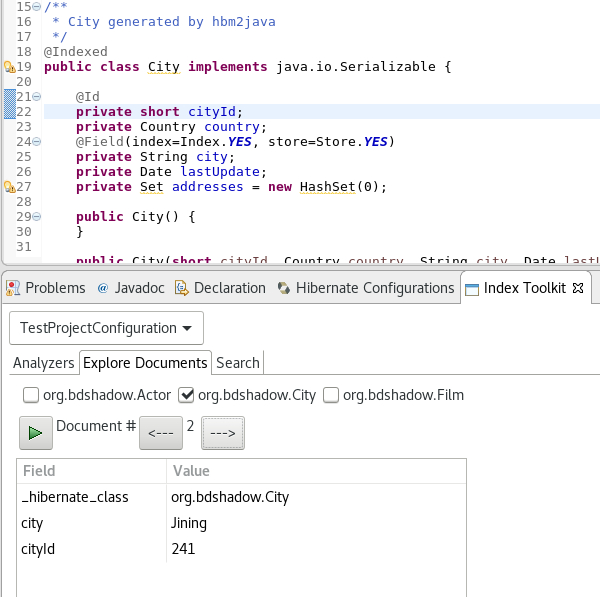
After creating the initial index you can now inspect the Lucene Documents it contains.
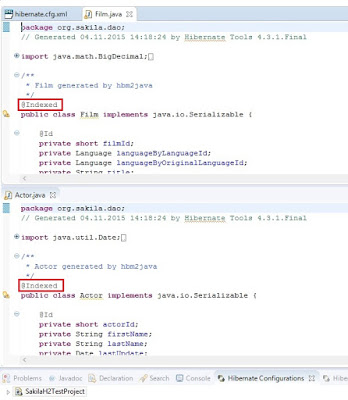
All entities annotated as @Indexed are displayed in the Lucene Documents tab.
Tick the checkboxes as needed and load the documents. Iterate through the documents using arrows.
Searching
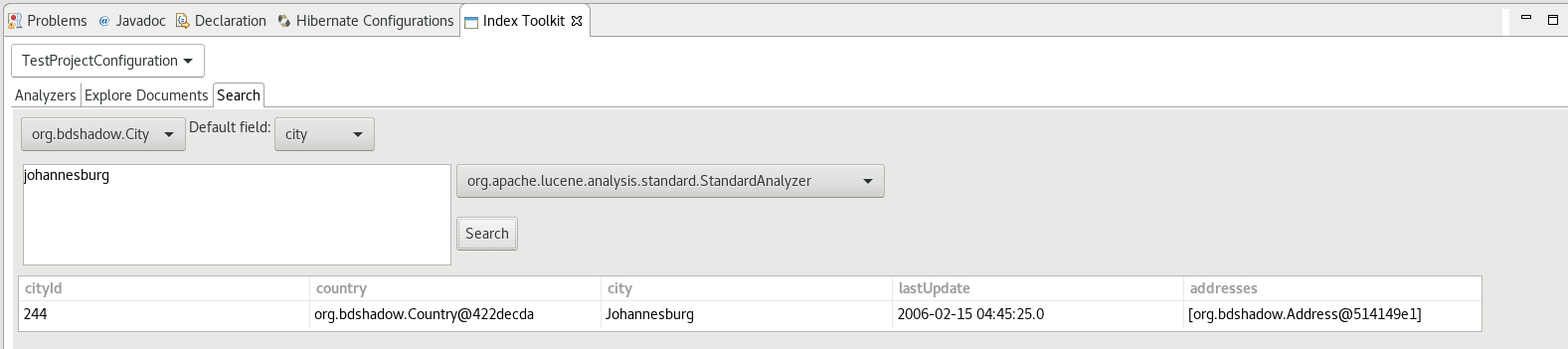
The plugin passes the input string from the search text box to the QueryParser which parses it using the specified analyzer and creates a set of search terms, one term per token, over the specified default field. The result of the search pulls back all documents which contain the terms and lists them in a table below.
OpenShift
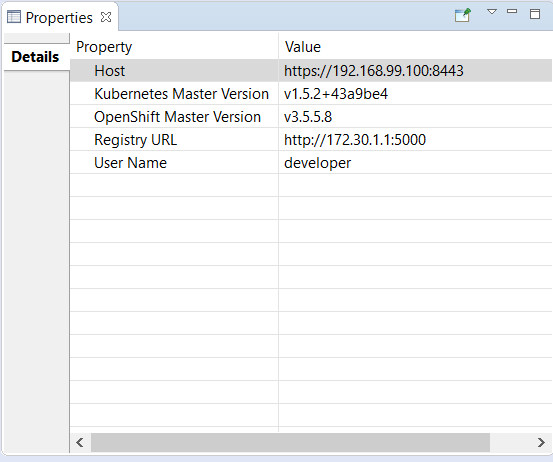
OpenShift server and Kubernetes server versions displayed
The OpenShift server and Kubernetes server versions are now displayed in the OpenShift connection properties. This information is retrieved using an un-authenticated request login to the OpenShift cluster is not required. This allow user to verify the OpenShift and Kubernetes level when interacting.
Here is an example based on an OpenShift connection against CDK3:
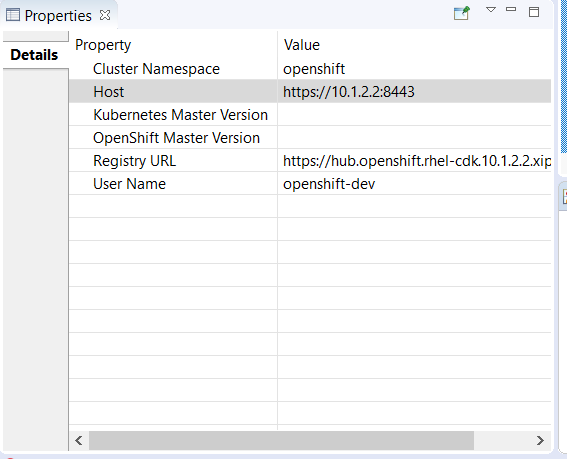
if the cluster is not started or accessible, then no values are displayed:
Related JIRA: JBIDE-24539
oc client selection per connection
Some operations (logs, file synchronization) require the user of the oc CLI client. It was possible to specific a single instance of the used oc CLI tool for the whole workspace. This may cause some trouble when working simultaneously with several OpenShift clusters (that may have different version levels). It is now possible to specify the oc CLI tool on the connection level. This is optional, and the default is to use the oc CLI tool specified at the workspace level.
The connection specific oc CLI tool is accessible through the OpenShift connection edit dialog with the Advanced button:
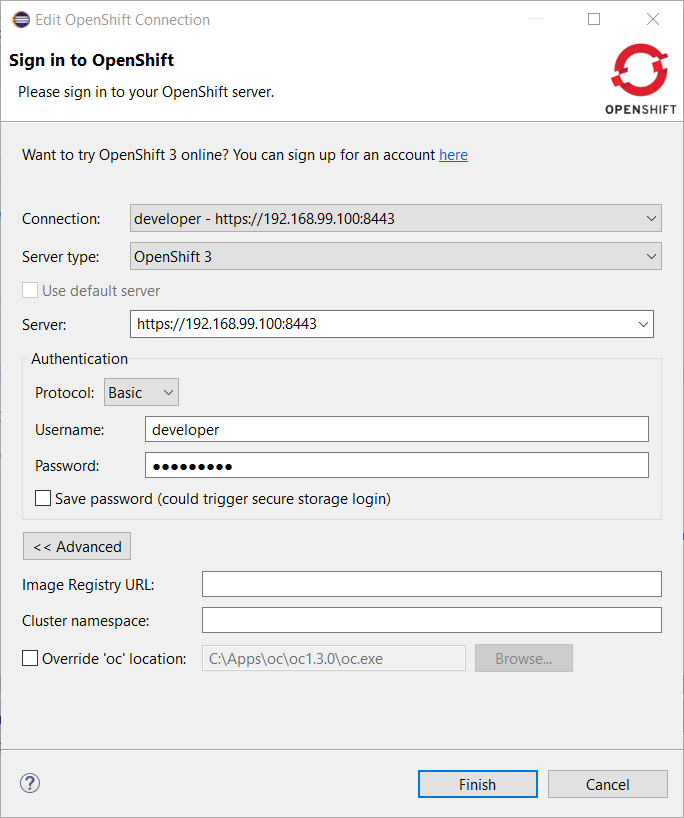
Enable the Override 'oc' location' flag and select a specific oc CLI tool for this connection through the *Browse button:
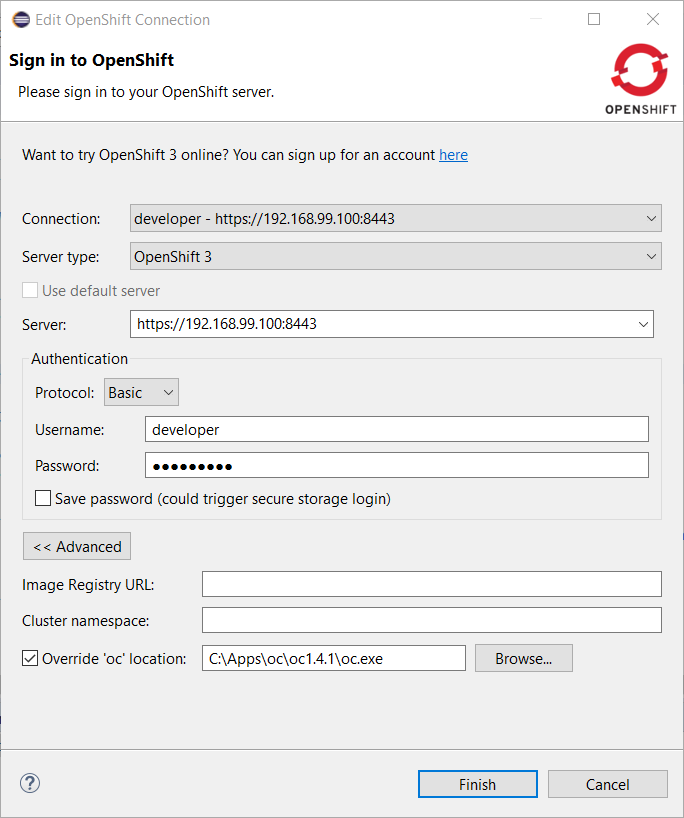
OpenShift connections created by the CDK server adapter will automatically have a specific oc CLI tool set as the CDK installs locally an oc CLI tool that is aligned with the embedded OpenShift version.
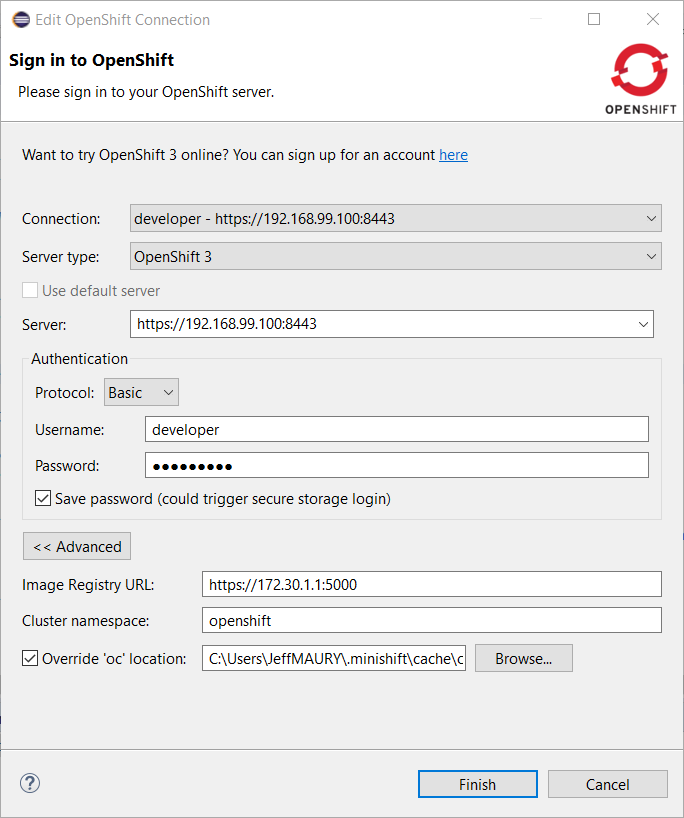
Related JIRA: JBIDE-24236
Server Tools
EAP 7.1 Server Adapter
A server adapter has been added to work with EAP 7.1. It’s currently released in Tech-Preview mode only, since the underlying WildFly 11 continues to be under active development with substantial opportunity for breaking changes. This new server adapter includes support for incremental management deployment like it’s upstream WildFly 11 counterpart.
Related JIRA: JBIDE-24508 - WF 11 / EAP 7.1 server adapter
Removal of Event Log and other Deprecated Code
The Event Log view has been removed. The standard eclipse log is to be used for errors and other important messages regarding errors during server state transitions.
Related JIRA: JBIDE-22717 - Remove all server log view code